卷积神经网络(CNN)在计算机视觉领域产生了许多新进展也衍生出了许多新型的网络,其中MobileNet就是CNN在轻量级网络的一个非常优秀的网络架构探索。近些年,为了追求分类准确度,模型深度越来越深,模型复杂度也越来越高,如深度残差网络(ResNet)其层数已经多达152层。
在某些应用场景如移动或者边缘嵌入式设备,大而复杂的模型是难以被应用的。模型过于庞大,面临着内存不足的问题,其次这些场景要求低延迟,或者说响应速度要快。所以,研究小而高效的CNN模型在这些场景至关重要,也是目前的一个主流方向。
目前的研究总结来看分为两个方向:一是对训练好的复杂模型进行压缩得到小模型;二是直接设计小模型并进行训练。不管如何,其目标在保持模型性能(accuracy)的前提下降低模型大小(parameters size),同时提升模型速度(speed, low latency)。本文的主角MobileNet属于后者,其是Google最近提出的一种小巧而高效的CNN模型,其在accuracy和latency之间做了一个balance。
Depthwise separable convolution
MobileNet的基本单元是深度级可分离卷积(depthwise separable convolution),它是一种可分解卷积操作,把常规的卷积过程分解为两个更小的操作:深度卷积(depthwise \ convolution)和逐点卷积(pointwise \ convolution),以减少计算量。
Depthwise convolution和标准卷积不同,对于标准卷积其卷积核是用在所有的输入通道上(input channels),而depthwise convolution针对每个输入通道采用不同的卷积核,就是说一个卷积核对应一个输入通道,所以说depthwise convolution是depth级别的操作。而pointwise convolution其实就是普通的卷积,只不过其采用的是1x1的卷积核。
分离卷积过程
下图分别为depthwise和pointwise的卷积过程:
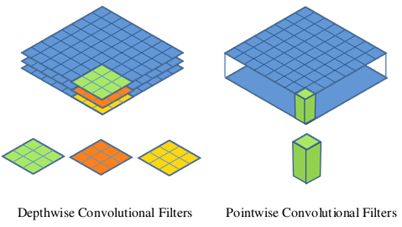
左边为depthwise卷积过程,绿、红、黄分别为三个不同的 $3\times 3 \times 1$的卷积核,每个卷积核分别与输入特征图对应的某一个通道做卷积运算,以此得到了一个通道数不变的新特征图。
右边为pointwise卷积过程,它以depthwise卷积的输出作为输入,以N个 $1*1$的卷积核做运算,得到一个新的通道数为N的特征图。
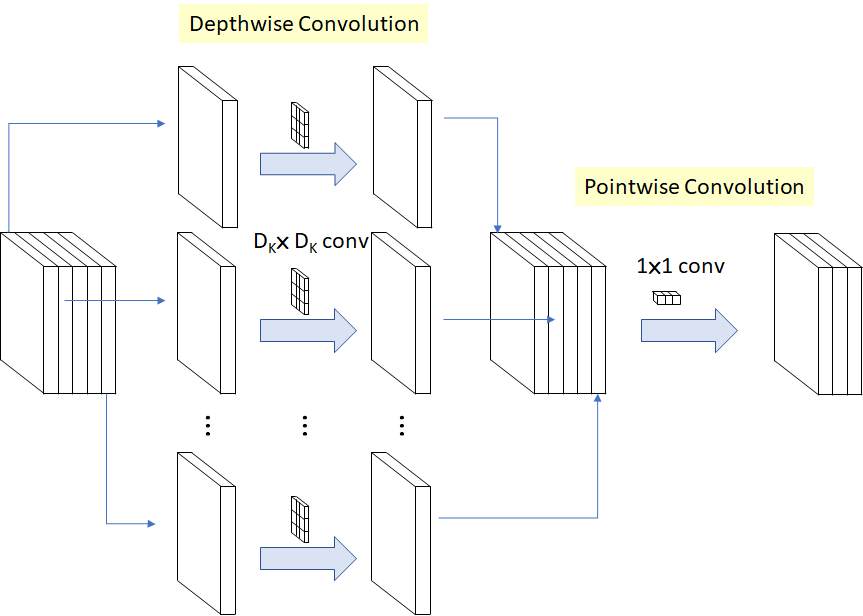
更加全面的过程可以看下面的流程图,注意图中箭头的指向:
计算量比较
常规卷积
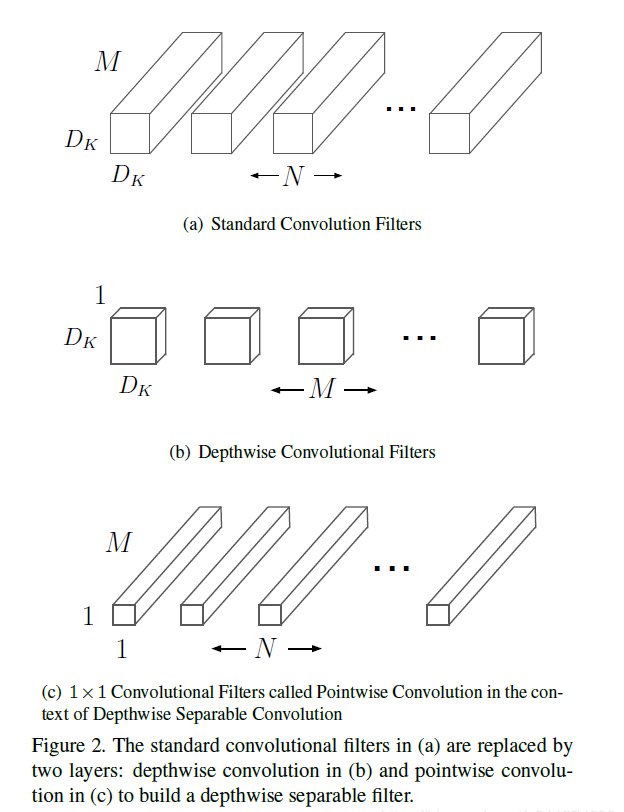
如上图(a),假设这一层的输入特征图维度为 $D_f \times D_f \times M (D_f为输入特征图宽高,M为通道数)$,假设卷积时使用边缘填充,则输出的宽高不变,该层输出为 $D_f \times D_f \times N(N为输出通道数)$,则对于卷积过程,需要N个维度为 $D_k \times D_k \times M (M为卷积核通道数)$的卷积核。
即卷积核的通道数必须等于输入特征图的通道数,而卷积核的个数是输出特征图的通道数。
因此,每一个卷积核包含的参数个数为 $D_k \times D_k \times M$个,此次运算所有卷积核参数为$D_k \times D_k \times M \times N $。
现在我们得到了卷积核和输入输出特征图的维度,那么可以计算出在卷积过程中进行的乘加运算次数(粗略计算):
其中 $D_k \times D_k \times D_f \times D_f$为一个卷积核在输入特征图的某一个通道进行的运算次数。
分离卷积
如上图(b),这一层的输入、输出特征图维度均与常规卷积相同。那么卷积过程分为2步:1.depthwise convolution,2.pointwise convolution。
depthwise convolution
对于depthwise convolution的过程,首先需要M个维度为 $D_k \times D_k \times 1$的卷积核。这些卷积核的通道数为1,因此只负责某一层的卷积运算,这也是为什么需要M个卷积核,因为输入特征图的每一个通道需要一个不同的卷积核。
在这一部分中,所有的M个卷积核,参数总个数为$D_k \times D_k \times 1 \times M$。
乘加运算次数为:
pointwise convolution
如上图(c),该卷积运算的过程与常规运算基本一致,差别在于pointwise convolution为N个 $1 \times 1 \times M$的卷积核。
这一部分中,参数个数为 $1 \times 1 \times M \times N$。
运算次数为:
分离卷积的总参数量为 $D_k \times D_k \times M + M \times N$。
总计算量为 式(2)+ 式(3):
参数量与计算量比较
因此,我们可以得出,相同输入和输出的分离卷积过程和常规卷积过程,参数量的比值为:
由于一般卷积神经网络中,卷积核大小为$3*3$,而卷积核个数为256、512或1024等,因此分离卷积的参数量大约为正常卷积的$\frac{1}{9}$。
由 式(1)和 式(4)可知,计算量的比值为:
与参数量的比值一致,因此分离卷积的计算量也大约为正常卷积的$\frac{1}{9}$。
PS:这里的乘加运算量为近似值,非准确计算。

上图为同样的MobileNet网络结构,使用正常卷积和深度可分离卷积的模型,在参数量和运算量上的比较,因为最后使用了全连接神经层,所以之间的比值要大于$\frac{1}{9}$。但是仍然可以看出,使用了深度可分离卷积之后,计算量的差距达到了一个数量级,而在ImageNet数据集上性能差距仅大约为1%。
之所以分离卷积可以大幅度减少计算量,实际上是因为分离卷积相比于正常的卷积方式,大大减少了特征提取的次数。常规卷积每个卷积核会对所有通道做特征提取,而depthwise卷积只会对每个通道做一次特征提取,之后的pointwise只是对提取的特征进行复用。也因此,网络的特征提取能力会较差一些。
除了减少计算量,另一方面,分离卷积增加了网络的深度,也就增加了添加非线性激活函数的次数。 在depthwise卷积和pointwise卷积之后,可以分别应用一个非线性激活层,既增加了非线性层的数量而又不显著增加参数和计算量。无论是ReLU,Softmax还是其他,激活层都是非线性的,这与卷积层不同。 “线的线性组合仍然是线”,而非线性层扩展了模型的可能性,所以“深层”网络比“宽层”网络更好。
因此,可以说,可分离卷积是通过减少单次卷积运算的特征提取能力,换取了更少的计算次数和更强的非线性拟合能力。
当然,仅仅以 FLOPs 计算量来表现网络的运行速度是不准确的,除非是同一种网络架构。确保这些运算能够有效实施也很重要。例如非结构化稀疏矩阵运算(unstructured sparse matrix operations)通常并不会比密集矩阵运算(dense matrix operations)快,除非是非常高的稀疏度。
这里需要注意的是,depthwise卷积的FLOPs更少,但是在相同的FLOPs条件下,depthwise卷积需要的IO读取次数比普通卷积要多得多。因此,由于depthwise卷积的小尺寸,相同的显存下,我们设置更大的batch来让GPU跑满,但是此时速度的瓶颈已经从计算瓶颈变成了GPU的IO瓶颈。
如果计算设备的IO带宽足够大,而浮点运算能力不高的情况下,典型的如CPU,使用depthwise卷积会有更大的收益。反之,即使浮点运算很快,但是受制于带宽速度,depthwise的运算速度不一定会比常规的卷积运算要快。
网络各部分比较
从上面的公式可以看出,大部分计算量与参数量都集中在pointwise卷积过程中,如果没有pointwise过程,则计算量可以降低到大约$\frac{1}{N}$。
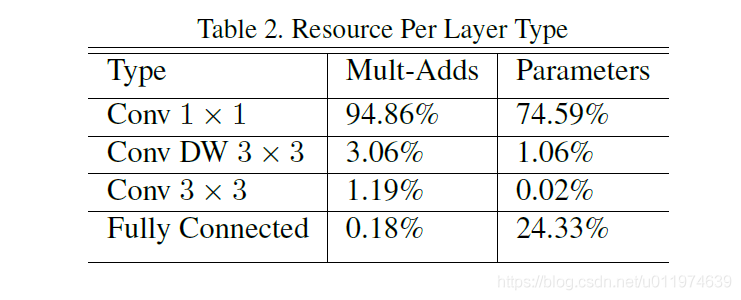
上表为Mobile net网络中所有不同部分的计算量和参数量比较。也可以看出,$1 \times 1$的卷积集中了整个网络接近95%的计算量和75%的参数量。
那么,为什么有了depthwise卷积之后还要加上耗费巨大计算量的pointwise卷积过程呢?
第一点,很明显,pointwise卷积可以用来改变输出的特征图的通道数。如果只有depthwise过程的话,输出只能和输入的通道数保持一致,无法改变。
第二点,个人看法。每一个卷积核代表了一种特征提取方式,但是有些提取出的特征需要进行组合才有意义。比如说一个卷积核用于x轴边缘检测,另一个卷积核用于y轴边缘检测,两个特征图组合在一起才是一个完整的边缘检测过程。所以需要pointwise过程,将各个通道的特征进行复用与融合,形成新的特征。有一种网络结构shuffleNet在group convolution之后使用channel shuffle打乱了通道顺序,也是一种对特征图通道进行操作的方式。
MobileNet 模型结构将几乎所有计算都放入密集的 1×1 卷积中(dense 1 × 1 convolutions),卷积计算可以通过高度优化的通用矩阵乘法(GEMM,最优化的数值线性代数算法之一)函数来实现。 卷积通常由 GEMM 实现,但需要在内存中进行名为 im2col 的初始重新排序,然后才映射到 GEMM。而 $1×1$ 卷积不需要在内存中进行重新排序,可以直接使用 GEMM来实现。
Mobile net
网络结构
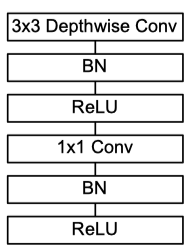
depthwise separable convolution,是MobileNet的基本组件,在真正应用中会加入batchnorm,并使用ReLU激活函数,所以depthwise separable convolution的基本结构如下图所示:
MobileNet网络结构如下图:
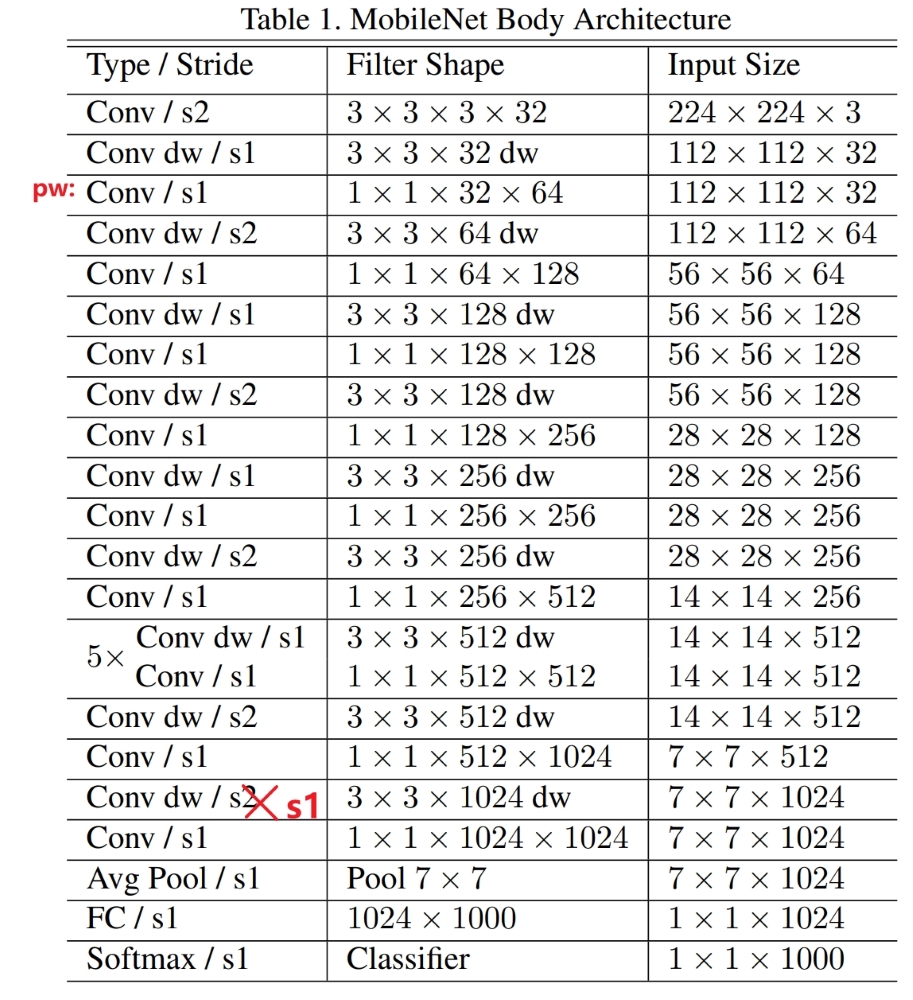
其中第三层红色标注’pw‘表明这一层为pointwise卷积,即为$1 \times 1$的卷积,下面的同理。另外倒数第五行的depthwise卷积的步长应该为s1,即$stride=1 \times 1$,应该是作者制作表格时弄错了。
剩下的网络结构就不再赘述了,图片中介绍得很详细。
网络性能
Mobile Net与比较流行的网络结构性能比较如下图:
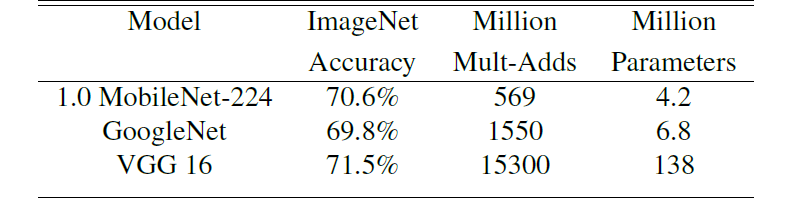
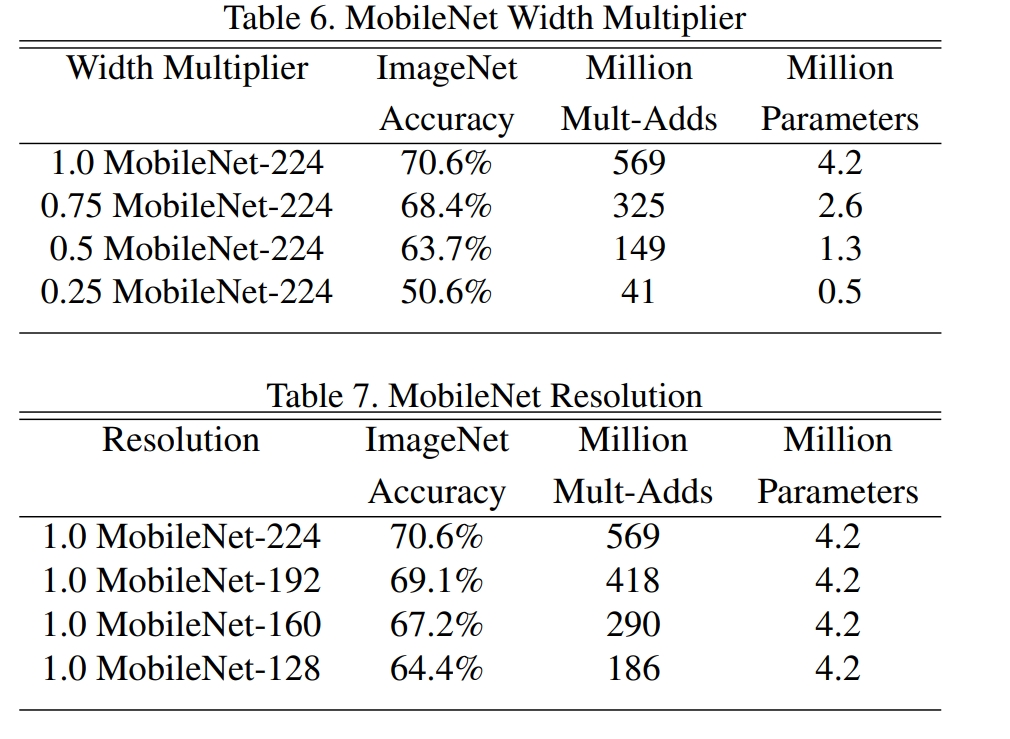
上表的1.0 MobileNet-224指的是输入图片分辨率为224的标准MobileNet模型。可以明显看出Mobile Net在计算量与参数量都远小于其他网络的情况下,在ImageNet数据集上的准确率可以保持大致接近。
因此,在数据量不大,分类数目不多,难度不太大的情况下,采用Mobile Net可以达到不错的效果,同时大大加快训练与推理速度,并且对于内存要求也比较低。
更小的MobileNet
MobileNet主打的是轻量级模型,那么肯定不会局限于只改变卷积方式,它在输入图片尺寸和网络中卷积的通道深度都是可以配置的。分别为宽度因子α (Width multiplier )和分辨率因子ρ(Resolution multiplier )。
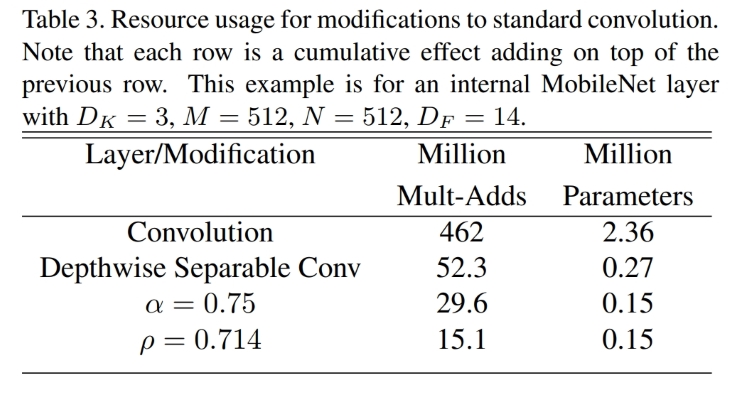
宽度因子α可以同时减少运算量和参数量,分辨率因子ρ只可以减少运算量。ρ=0.714一行表示输入图片尺寸为160*160,并同时设置α=0.75。
Width Multiplier
尽管不如全连接层的神经元个数代表该层的宽度那么直观,卷积层的通道数也可以代表改卷积层的宽度。而卷积层的深度则表示网络的深度。一般而言,一个”窄而深“的网络表现要好于“宽而浅”的网络。
控制模型宽度的超参数是:宽度因子α (Width multiplier ),用于控制输入和输出的通道数,即输入通道从M 变为αM,输出通道从N 变为αN。α 的范围为(0,1],一般会取值为0.25,0.5,0.75,1。(如果宽度因子α * 标准网络的通道数不等于整数,直接用int取整)
宽度因子α 可以调节网络的宽度,从而进一步减少计算量。举个例子,标准的1.0 MobileNet-224网络的第一层为通道数为32的正常卷积,第二层为通道数为32的depthwise卷积。而α =0.5的0.5 MobileNet-224网络,第一层为通道数为16的正常卷积,第二层位通道数位16的depthwise卷积。
对于depthwise separable convolution,其计算量变为:
和常规卷积方式的计算量相比:
宽度因子将计算量和参数降低为约$\alpha^2$倍,可很方便的控制模型大小.
理论上,宽度因子α是控制卷积神经网络宽度的因子,不仅仅局限于MobileNet,常规的卷积神经网络也可以通过设置宽度因子来使得模型变窄从而减小模型和加快运算速度。
Resolution multiplier
第二个控制模型大小的超参数是:分辨率因子ρ(resolution multiplier ),用分辨率因子控制图片的分辨率和输入特征图的宽高,以此减少乘加运算的次数。
可设置ρ ∈ ( 0 , 1 ] ,来控制输入分辨率为$224 \times \rho $,而在tensorflow中,只能设置输入分辨率为224 , 192 , 160 和 128。
标准的1.0 MobileNet-224模型中,图片输入到网络前会被放缩,限制在224×224的pixel,然后输入到模型中。而分辨率因子会进一步限制输入图片的尺寸为$(224\times \rho)* (224\times \rho)$。
在上述两种方法都使用的情况下:
同样的,缩减输入图片分辨率也是其他网络常用的方法之一。
使得网络变窄以及使得图片变小在加快网络速度的同时,也会降低网络的精度。下图为分别改变α和ρ的结果:
使用者可以根据自己的设备算力和问题复杂程度调整这两个参数,来灵活应对不同的问题。
Tensorflow实现
MobileNet已经收录在tensorflow的applications中,见此GitHub地址。
并且有在ImageNet上训练好的模型可以直接使用。
个人感想
我个人还是很喜欢MobileNet找一个网络结构的,虽然它的精度比不上ResNet,但是实际情况下我还是会经常用到它。在许多不是特别复杂的任务中,通过预先处理数据,剔除掉一些干扰特征,这个网络也可以表现得很不错。
而且分组卷积也是一个非常符合人类思维的结构。在上学那会,因为先接触到的是灰度图的数字图像处理,图像处理里的灰度图的空域变换都是用的厚度为1的算子卷积图像,所以刚刚接触到CNN的时候,我对卷积过程中卷积核的形状产生过疑惑,我总以为卷积核就是一个3*3*1的形状。即使后来理解了仍然会好奇为什么每一个通道需要使用不同的算子。而分组卷积正好就是不同的通道使用同一个算子从而减少参数量。

